
Suurin osa data-analyytikon sprintistä kului oikean datan etsinnässä ja datavirheiden korjaamisessa. Migraatio ei onnistunutkaan aiotulla tavalla. Asiakas ihmetteli, miksi juuri hänelle kohdennettu markkinointiviesti alkoi sanoilla “Hyvä herra ETUNIMI SUKUNIMI”. Yrityksessä on huomattu, ettei raportointi välttämättä pidä paikkaansa ja näin ollen liiketoiminnan raportointiin ei voitu täysin luottaa.
Nämä ovat kaikki ilmentymiä tai seurauksia huonosta datan laadusta.
Tässä blogitekstissä käsitellään perusteita datan laadun hallinnasta ja siitä, mitä lisäarvoa datakatalogit voivat datan laadun hallintaan tuoda.
Datan laatu
Huono datan laatu aiheuttaa muun muassa väärin perustein tehtyjä päätöksiä, liiketoiminnan tehottomuutta, luottamuksen puutetta, hukattuja mahdollisuuksia ja menetettyä liikevaihtoa. Gartner on arvioinut, että huono datan laatu aiheuttaa keskimäärin yrityksille vuosittain 15 miljoonan dollarin taloudelliset menetykset muun muassa edellä mainittujen tekijöiden seurauksena. Heikolla datan laadulla voi myös olla epäsuoria vaikutuksia. Tällöin datavetoisen yrityksen voi olla haastavaa pitää työntekijöitään töissä, jos sillä on tarjota heille vain huonolaatuista dataa – onhan data myös työkalu yhä useammalle. Keskeistä on ymmärtää, että muodostuivatpa datan laadun kustannukset mitä kautta tahansa, on huonolaatuiselle datalle aina tavalla tai toisella laskettavissa hintalappu.
Datan laadun kustannukset ovat sitä suuremmat, mitä myöhäisemmässä vaiheessa niihin vastataan – pahimmassa tapauksessa niille ei tehdä mitään. Näin ollen organisaatioilla on kannustin löytää ratkaisuja datan laadunhallintaan. Datan laadunhallinnan voi karkeasti jakaa kahteen eri tasoon: datan laadun ongelmien tunnistamiseen ja monitorointiin sekä datan laatuongelmien ratkaisuun. Kaksi tasoa kulkee erottamattomasti käsi kädessä, ja kummastakaan ei ole hyötyä ilman toista. Molempien toteuttamiseen on tarjolla työkaluja, mutta keskeistä on se, kuinka organisaatio – eli siellä työskentelevä joukko ammattilaisia – on datan laadun ja datan hallinnan osalta järjestäytynyt.
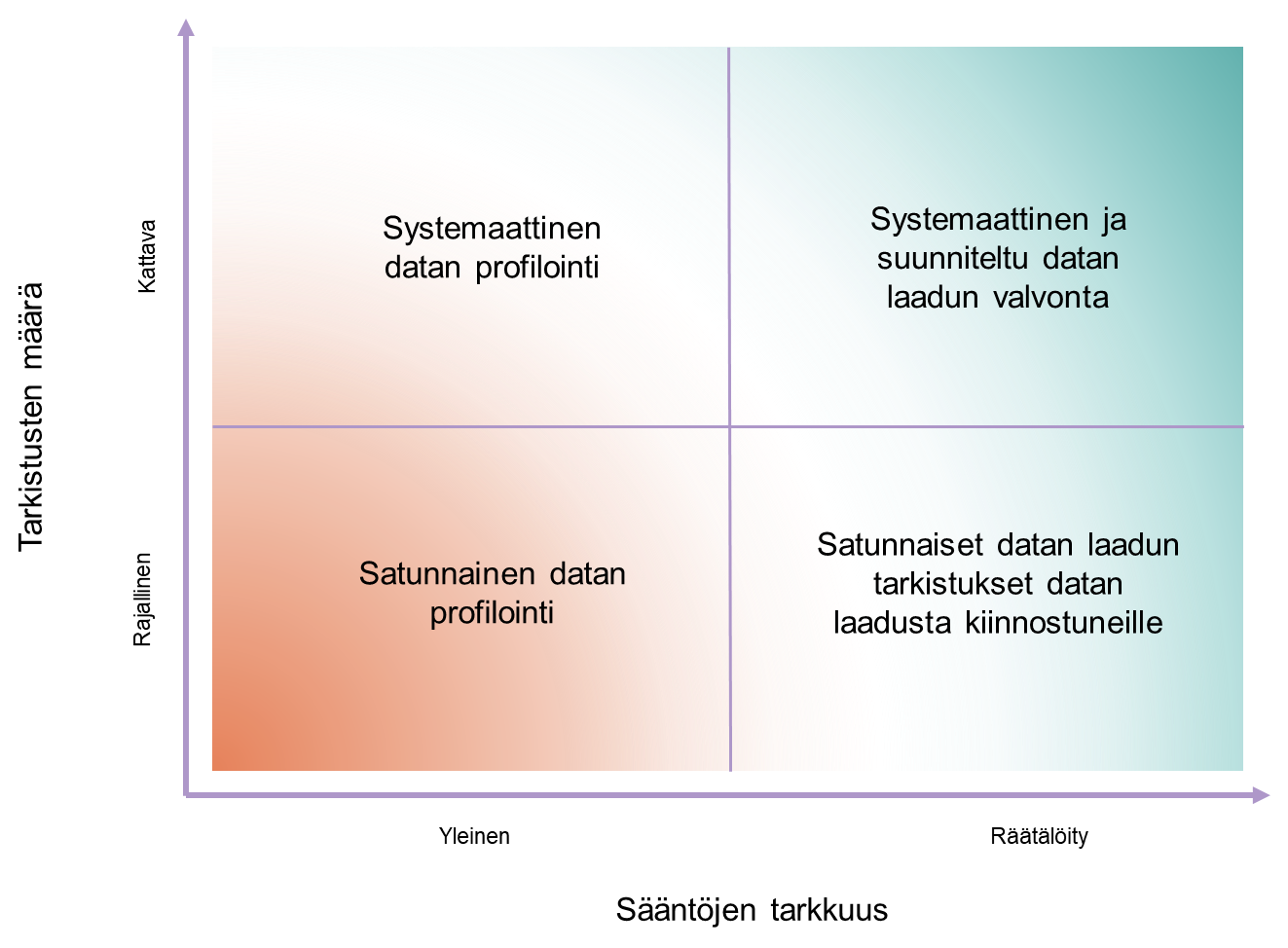
Kuva 1 Datan laadun nelikenttä
Datan laatuongelmien tunnistamista ja datan laadukkuuden monitorointiin on monta erilaista lähestymistapaa. Kehittämässämme nelikentässä lähestymistapoja jäsennetään kahden ulottuvuuden perusteella: tarkistusten määrän ja toisaalta sääntöjen tai tarkistusten tarkkuuden perusteella. Satunnainen datan profilointi tarkoittaa tilannetta, jossa datan laadun tarkastuksia tehdään siellä täällä ja jokainen taho omissa siiloissaan. Lisäksi tarkastukset ovat luonteeltaan mekaanisia, eli tarkastellaan kentän täyttöastetta tai täyttääkö kentässä oleva tieto muodolliset vaatimukset.
Systemaattinen datan profilointi puolestaan tarkoittaa tilannetta, jossa joko lähes kaikelle organisaation datalle tai vähintään keskeiselle datalle tehdään säännöllisesti muodollisia tarkistuksia ja monitorointia. Tarkistuksista on sovittu ja ne tehdään tietyllä kaavalla. Nelikentän vasemmalla puolella ja etenkin vasemmassa yläreunassa datan laadun sääntöjen määrä voi olla esimerkiksi kymmeniä tuhansia, jos jokaisen taulun jokaisesta kentästä tarkastetaan esimerkiksi täyttöaste ja vaatimustenmukaisuus. Profiloinnin vahvuutena on, että sillä tuotetaan erittäin paljon tietoa datan laadusta kattavasti ympäri organisaatiota. Kerätyt tiedot eivät välttämättä kuitenkaan kerro kovinkaan tarkasti todellisuudesta. Lisäksi tarvitaan asiantuntijaa tunnistamaan, onko kyseessä todella tietovirhe. Esimerkiksi jos kenttä kuvaa asiakkaalla olevien luottotietomerkintöjen määrää, ei ole oletettavaa, että kaikilla asiakkailla on sellainen. Näin ollen kentän heikko täyttöaste voi äkkiseltään näyttäytyä datan laadun virheenä, vaikkei se sitä välttämättä ole.
Nelikentän oikeassa alakulmassa sääntöjen tarkkuus kasvaa, mutta määrä pienenee. Yleensä tämä tarkoittaa sitä, että kaikkea dataa ei huomioida ja tarkistuksissa säännöt on kehitetty liiketoiminnan lähtökohdista. Säännöt on kustomoitu monitoroimaan tiettyjä kriittiseksi tunnistettuja datoja tai sellaisia datoja joiden laadun tiedetään heikkenevän nopeasti. Esimerkiksi verkkokaupan asiakasdatan laatua arvioidessa on syytä ottaa huomioon vain se osa datasta, joka koskee verkkokaupan asiakkaita tai potentiaalisia asiakkaita. Sääntöjen määrä voi olla kymmeniä, mutta ne mittaavat juuri tälle liiketoiminnalle keskeisten toimintojen datan laatua. Tässä tapauksessa laatua ei mitata systemaattisesti, vaan mittarit on tehty yksittäisten toimintojen tarpeisiin ja kokonaiskuvaa datan laadusta on mahdoton muodostaa. Nelikentän oikean alakulman tilanteeseen ajaudutaan usein siitä syystä, että jokin viranomainen edellyttää organisaatiolta raportointia joidenkin tietojen laadusta.
Viimeiseksi ollaan nelikentän oikeassa yläkulmassa, jota pidämme datan laatuongelmien tunnistamisen ja monitoroinnin ihannetilana. Oikea yläkulma kuvaa tilannetta, jossa datan laatua mitataan ja tarkastellaan systemaattisesti yhdessä sovituilla menetelmillä. Tiedon laadun ongelmien tunnistamisessa on lähdetty liiketoiminnan tarpeista ja liiketoiminnalla on työkalut tunnistaa, mikäli heille keskeiset tiedot ovat huonolaatuisia. Datan laadusta on mahdollista muodostaa systemaattinen kokonaiskuva ja sitä voivat tarkastella ja helposti ymmärtää kaikki, jotka ovat kiinnostuneita datan laadusta. Samalla datan laadun kehitystä voidaan seurata ja monitoroida. Tämä tarkoittaa luonnollisesti sitä, että laadun korjausten vaikuttavuus voidaan osoittaa. Hyvä datan laadun hallintamalli hyödyntää sekä kattavaa profilointia että liiketoiminnalle räätälöityjä sääntöjä ja kasvattaa mahdollisimman monen luottamusta dataan. Datavetoisessa organisaatiossa jokaisen dataa jollain tavalla hyödyntävän on voitava luottaa, että data on oikein.
Kuten aiemmin mainittu, datan laadun ongelmien tunnistaminen on keskeistä, jotta datan laatua voidaan lähteä parantamaan. Se ei kuitenkaan yksin riitä. Tarvitaan yhteisesti sovittu toimintamalli siitä, mitä toimia datan laadun parantamiseksi tulee tehdä. Itseasiassa datan laadun ongelmien tunnistaminen on lähes merkityksetöntä, jos ne eivät aiheuta jotain toimintaa datan parantamiseksi. Kaiken datan laadun työn pitäisi lopulta tähdätä siihen, että data ja jokainen sitä hyödyntävä toiminto, esimerkiksi raportointi, on luotettavaa.
Mikä on datakatalogi ja miten se liittyy datan laatuun?
Datakatalogi on työkalu, joka kokoaa yhteen organisaation tietoresurssit ja muun muassa liiketoiminnan käsitteet sekä näiden väliset riippuvuudet. Teknisesti määriteltynä datakatalogi on metatiedon hallinnan työkalu, joka hyödyntää organisaation liiketoiminnallista, operatiivista ja teknistä metadataa. Hyvin toteutetusta datakatalogista kuka vain käyttäjä voi helposti löytää mitä dataa organisaatiossa on ja esimerkiksi, miten se liittyy organisaation liiketoimintaan.
Uskallamme Loihteessa väittää, että datasta saadaan sitä parempilaatuista, mitä laajemmin organisaatiossa ymmärretään dataa. Tämä edellyttää, että mahdollisimman moni pääsee näkemään dataa ja ennen kaikkea tulkitsemaan sitä. Datakatalogit on luotu ratkaisuiksi juuri tähän tarkoitukseen. Lisäksi katalogit tarjoavat reilun työkalupakin verran ominaisuuksia, jotka tuottavat lisäarvoa metadatojen avulla.
Yksi keskeinen ja monissa katalogeissa ilmentyvä tieto on, kuka vastaa mistäkin datasta. Katalogeissa voidaan näyttää tiedot siitä, kenen vastuulle minkäkin datan hyvänlaatuisuus ja luotettavuus kuuluvat. Omistajuuksia voidaan määritellä esimerkiksi datalähteiden, yksittäisten taulujen tai liiketoiminnan sanaston ja siihen liittyvien datojen perusteella. Keskeistä on, että datan laatuun liittyvät prosessit ja roolit, mukaan lukien datan laadun korjaus, on sovittu ja dokumentoitu. Katalogi toimii erinomaisesti datan laadun operatiivisen työn sekä data governancen tukena. Hyvässä datan laadun hallintamallissa myös vastuut ja velvollisuudet laatuvirheiden korjaamisesta tulee olla määriteltynä.
Lisäksi monet datakatalogityökaluista tarjoavat mahdollisuuden profiloida dataa. Jos katsotaan yllä esitettyä datan laadun nelikenttää, katalogin avulla voidaan päästä systemaattiseen datan profilointiin ilman erillisiä datan laadun toimenpiteitä. Datakatalogien profilointiominaisuudet tarjoavat mahdollisuuden kattavalle datan laadun ongelmien tunnistamiselle (data quality mining). Systemaattisen profiloinnin vahvuus on, ettei tällöin tarvitse tietää tarkasti, missä tiedon laadun ongelmat ovat. Profilointi tuottaa geneeristen mittausten perusteella arvokasta tietoa, joka yhdistettynä asiantuntijan tulkintaan voi tuottaa merkittäviä datan laatuun liittyviä havaintoja. Esimerkiksi tuotetiedolla voi olla yksi omistaja tai tietovastuullinen. Katalogin avulla tämä henkilö – ja kuka tahansa muu – voi parilla klikkauksella nähdä, mikä kaikki data on tuotetietoa. Lisäksi katalogien profilointiominaisuuksien avulla voidaan nähdä missä kunnossa tuo data on.
Data lineage on edellä mainittujen lisäksi yksi keskeinen datakatalogien ominaisuus. Teknisesti ilmaistuna datan data lineage kuvaa visuaalisesti datan esiintymishistorian sille annettujen ETL- tai ELT-prosessien tai manuaalisten määritysten avulla. Vähemmän teknisesti ilmaistuna se kuvaa datan polun aina sen luomisesta lähdejärjestelmässä sen hyödyntämiseen esimerkiksi raportoinnissa. Välissä voi olla useita muita järjestelmiä ja esimerkiksi rikastuksia ulkoisista lähteistä. Lineagen avulla voidaan esimerkiksi vastata kysymykseen: mistä kaikkialta verkkokaupassa tuotteelle esitetty hinta tulee ja mitä sille matkalla tapahtuu?
Data lineagen avulla asiaa voidaan myös tarkastella toisesta kulmasta. Jos data syntyy järjestelmässä, minne kaikkialle se sieltä kulkee? Missä kaikkialla sitä hyödynnetään? Datan laadun keskeinen periaate on toteuttaa datan laadun korjaukset mahdollisimman alkulähteillä. Jos profiloinnin avulla tunnistettiin ennalta tuntemattomia tiedon laadun ongelmia, data lineagen avulla voidaan paikantaa ongelmalle sopiva korjauspiste, jotta tietojen laadukkuus voidaan varmistaa kerralla mahdollisimman moneen paikkaan. Lisäksi sen avulla voidaan paikantaa helposti datan laadun monitoroinnin pisteet.
Metadatojen hallinta ja datan laatu liittyvät keskeisesti yhteen ja molempien ominaisuudet löytyvät jo useasta työkalusta. Monen markkinoilla olevan työkalun filosofia lähtee kokonaisvaltaisesta datojen hallinnasta (data management). Hyvän datan hallinnan taustalla on ajatus siitä, että data on mahdollisimman läpinäkyvää, hyvin saavutettavaa, luotettavaa ja soveltuvaa jokaiseen sen käyttötarkoitukseen.
Miten Loihde voi auttaa?
Loihde on asiantuntija datan laadussa, datakatalogeissa ja datan hallinnassa. Autamme organisaatiotasi datan laadun kysymyksissä aina tavoitetilan muodostamisesta kokonaisvaltaisen operatiivisen datan laadunhallinnan malliin suunnitteluun ja käyttöönottoon. Lisäksi voimme auttaa sinua soveltuvien teknologioiden löytämisessä. Haluamme auttaa sinua menestymään tiedon johtamisessa. Datakatalogit ja datan laatu ovat hyviä lähestymistapoja tähän.
Ota yhteyttä:
Tuomas Luukkonen
Data Catalog Lead
tuomas.luukkonen@loihde.com
+358 50 362 1515


