Tekstin ovat kirjoittaneet Aureoliksen Eevi Lappalainen ja Ville Huikari yhteistyössä.
Me suomalaiset haluamme ainakin uskotella itsellemme, että suomen kieli on pirun hankala oppia. Olipa väittämä myytti tai ei, sama ajatusmalli siirtyy helposti suomenkielisen tekstidatan analysointiin. Eivät algoritmit näin harvinaista kieltä ymmärrä, koneethan puhuvat englantia. Mutta onko asia todella näin? Uskaltaako suomenkielistä tekstidataa lähteä analysoimaan?
Aureolis oli mukana tämän vuoden Hackathon in SAS® Viya® 2019 -kilpailussa. Tässä yhteydessä louhimme suomenkielistä dokumenttidataa, joka sisälsi vapaamuotoista kuvailua sairauksista ja terveysriskeistä. Tavoitteena oli tunnistaa, mihin sairauteen yksittäiset dokumentit liittyvät sekä luokitella dokumentteja tämän perusteella. Hackathon-projekti vahvisti uskoamme siihen, että suomenkielistä tekstidataa voi ja kannattaa analysoida.
Mitä on tekstianalytiikka?
Monilla aloilla tiedon analysointi perustuu pääosin rakenteellisessa muodossa olevaan lähdedataan. Usein suuri osa informaatiosta on kuitenkin varastoitu strukturoimattomana tekstidatana. Tekstianalytiikka tarjoaa keinoja mielenkiintoisten ilmiöiden ja aiheiden etsimiseen näistä datalähteistä.
Tekstianalytiikan tavoitteena voi olla esimerkiksi vapaamuotoisten tekstidokumenttien luokittelu ennalta tiedettyihin tai vielä tuntemattomiin ryhmiin, kuten Hackathon-projektin kohdalla. Lisäksi tavoitteina voivat olla sentimenttianalyysi, eli tekstidokumenttien sävyn (positiivinen, neutraali, negatiivinen) tunnistaminen tai isossa tekstimassassa usein esiintyvien termien tai aiheiden tunnistaminen ja analysointi.
Parsitaan ja stemmaillaan
Vapaamuotoisen tekstin analysointiprosessin olennainen osuus on ns. Text Parsing -vaihe. Lyhyesti tämä tarkoittaa tekstin kääntämistä ihmisluettavasta muodosta koneluettavaan. Käytännössä pitkät tekstit pilkotaan erillisiin sanoihin, joita seuraavassa vaiheessa voidaan lähteä analysoimaan. Yhtenä osana parsing-vaihetta on sanojen stemmaus (Stemming). Tällä tarkoitetaan sanan palauttamista juureen tai perusmuotoon. Tämän jälkeen kone osaa niputtaa eri taivutusmuodot samasta sanasta yhdeksi (koira, koirakaan, koirankaan, koiraakaan, …).
Aluksi voidaan todeta, että analyyseissä käytetty SAS Viya Visual Text Analytics -työkalu selviytyy suomen kielestä jo lähtökohtaisesti hyvin. Työkalu tukee suomenkielistä tekstianalytiikkaa, ja sen Text Parsing -toiminto osaa useimpien sanojen parsimisen ilman mitään konfigurointia.
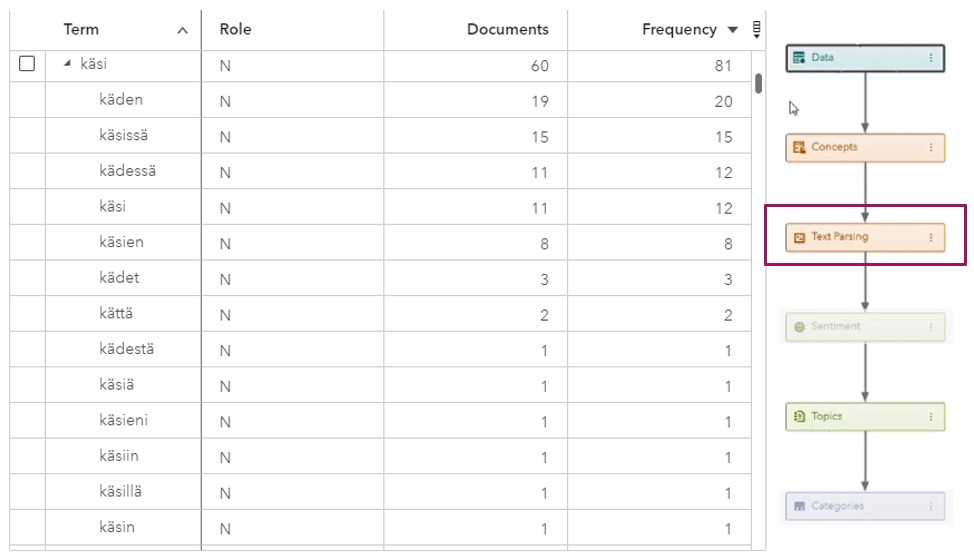
Kuva. SAS Visual Text Analytics on löytänyt datasta sanan “käsi” eri muodot.
Tekstin parsimisen jälkeen työkalu luo automaattisesti aiheluokkia, topiceja. Analyysin tässä vaiheessa tekstidokumentit jaetaan tilastollisia menetelmiä hyödyntäen aihealueiden mukaan luokkiin.
Automaatio nopeuttaa analyysiä, mutta vain ihminen ymmärtää tekstin sisällön
Vaikka pääpiirteissään automaattinen tekstin parsiminen ja luokittelu toimi Hackathon-projektissa suomeksi yllättävän hyvin, analyysien hiomisessa tarvitaan suomen kielen osaamista ja aihealueen tuntemusta.
Tekstin parsimisvaiheessa ohjelmisto oli tehnyt myös virheitä, esimerkiksi tulkinnut samankaltaisia sanoja toistensa synonyymeiksi tai määritellyt substantiiveja pronomineiksi. Toisaalta aineistossa itsessään oli kirjoitusvirheitä ja lyhenteitä, joita kone ei osannut tunnistaa. Myöskään homonyymien eli muodoltaan samanlaisten mutta merkitykseltään erilaisten sanojen tunnistaminen oikeassa kontekstissaan ei ainakaan vielä luonnistu algoritmeilta, joille sana ”kuusi” on sama, oli se sitten joulukuusi tai numero.
Koska ohjelmisto ei ”ymmärrä” sanojen todellista merkitystä, sen generoimat luokitukset eivät aina olleet loogisia. Esimerkiksi usein yhdessä esiintyvät termit saattavat sotkea tuloksia. Myös samankaltaiset termit voivat johtaa konetta harhaan. ”Toimistotyö” ja ”toimistosiivous” oli niputettu saman topicin alle, vaikka ihmislukijalle on itsestään selvää, että kyseessä on kaksi hyvin erilaista työtehtävää.
SAS:in algoritmin luomien automaattisten analyysien jälkeen tulee analyytikon siis nähdä vaivaa sen eteen, että Text Parsingin ja topicien generoinnin tulokset ovat järkeviä.
Nopeita tuloksia tekstianalytiikan avulla
Suomen kieli ja kielioppi eivät siis ole tekstianalytiikan työkaluille ylitsepääsemätön ongelma. Ohjausta totta kai tarvitaan, mutta toisaalta tekstin analysointi on jatkuva iterointiprosessi:
- aja data prosessin läpi
- tarkastele luokittelun tuloksia
- katso, mitkä tiedot eivät luokitu tai luokittuvat väärin
- selvitä, mistä virheet johtuvat ja muokkaa analyysiä
- aja analyysit uudestaan
Hackathon-projektissa noin 80 % tekstidokumenteista saatiin luokiteltua melko pienellä työmäärällä niissä esiintyvien sairauksien mukaan. Käyttökohteita tähän liittyen on helppo keksiä. Suoraviivaisin ja yleistettävin sovelluskohde voisi olla tekstidokumenttien manuaalisen käsittelyprosessin avustaminen ja tehostaminen. Tekstianalytiikka mahdollistaisi myös trendien ja ilmiöiden tunnistamisen datasta.
Uskaltaako suomenkielistä tekstidataa siis lähteä analysoimaan? Koneet ja algoritmit eivät hankalaksi väitettyä suomen kieltä säikähdä, älä siis säikähdä sinäkään. Monet tekstianalyysissa vastaan tulleet ongelmat, kuten synonyymien oikea tunnistaminen, eivät ole mitenkään suomen kielelle uniikkeja ongelmia. Vastaavanlainen mallin ohjaus on todennäköisesti tarpeen, käsiteltiin aineistoa millä kielellä tahansa.
Case-videon voi käydä katsomassa täältä: https://bit.ly/2TAuJnc


