Tässä blogisarjassa tulemme esittelemään hyödyllisiä työkaluja visuaaliseen analytiikkaan. Käytännössä esittelemme siis erilaisia tapoja visualisoida tietoa ja pyrimme tuomaan esille konkreettisiä käyttötapauksia.
Ensimmäisenä otamme käsittelyyn vanhan kunnon Scatterin (hajontakuvio / sirontakuvio / jne). Kyseessä on hyvin yksinkertainen, mutta tehokas tapa esitellä tietoa kahden mittarin (muuttujan) ja yhden tai useamman ulottuvuuden avulla.
Perinteisesti kuviota käytetään tilastotieteessä muuttujien keskinäisen riippuvuuden vertailuun. Pelkkien korrelaatiokertoimien tarkastelu voi joissakin tapauksissa johtaa virheellisiin tulkintoihin ja parempaan käsitykseen muuttujien välisestä riippuvuudesta voi päästä scatter-kuvion avulla. Ajatellaan esimerkiksi tilanne, jossa haluttaisiin ennustaa jotakin jatkuvaa vastetta (esim. myyntiä) ja käytössä olisi iso data, joka sisältää paljon muuttujia. Ensimmäinen steppi olisi tutkia, että millä kaikilla tekijöillä voisi olla vaikutusta ennustettavaan vastemuuttujaan. Tällaisessa analyysissä scatteria on hyvä hyödyntää, eli piirrettäisiin hajontakuvioita myynnin ja muiden jatkuvien muuttujien välille ja katsottaisiin, missä näkyy yhteyksiä. Tämän perusteella taas voitaisiin lähteä rajaamaan ennustukseen käytettävää muuttujajoukkoa.
Toinen käyttökohde scatter-kuviolle voisi olla esimerkiksi poikkeavien havaintojen tai virheellisten kirjausten metsästys. Ajatellaan vaikkapa terveystutkimusta, jonka yhteydessä tutkittavilta mitataan keuhkojen tilavuutta. Paikkakunnalla X on kolme tutkimuspistettä ja näistä yhdessä mittauslaite on kalibroitu väärin ja se näyttää systemaattisesti aivan liian suuria lukuja. Tämä ongelma saattaa jäädä huomaamatta pelkästään numeroita tarkastelemalla. Mutta kun piirretään scatter-kuvio tutkittavien pituuden ja keuhkojen tilavuuden välille ja väritetään tutkimuspisteitä koskevat mittaukset eri väreillä, niin mittausvirhe saattaakin pompata esiin.
Mutta otetaanpa yksi konkreettisempi esimerkki scatter-kuviosta:
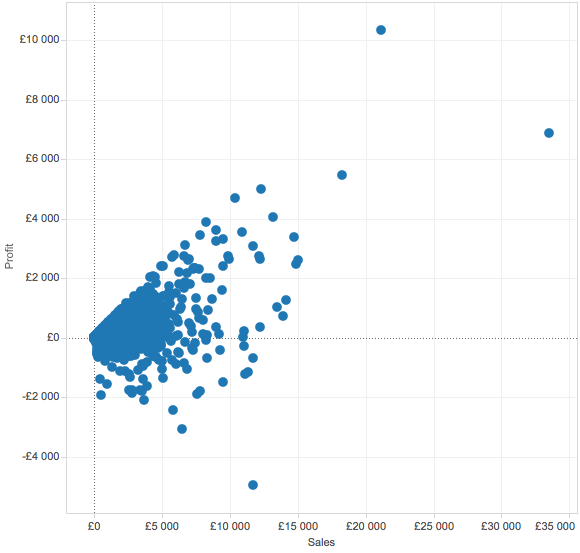
Ylläolevassa esimerkissä jokainen piste on tuote, x-akselilla myynti ja y-akselilla kate. No mitäs tämä nyt kertoo? Visualisoinnista näkee heti, mitkä tuotteet myyvät eniten ja minkä kate on suurin. Mukavintahan olisi nähdä mahdollisimman paljon pisteitä oikeassa yläkulmassa.
Scatterin tietoa voisi tulkita karkeasti näin:
- Oikeaa yläkulmaa lähestyvät tuotteet myyvät paljon ja erittäin hyvällä katteella -> Hyvä juttu, näitä tuotteita kannattaa myydä jatkossakin ja hinnoittelukin tuntuu olevan suurinpiirtein kondiksessa.
- Oikeaa alalaitaa lähestyvät tuotteet myyvät paljon, mutta kate on huono (jopa miinuksella) -> Kannattaisiko/pystyisikö nostaa hintaa?
- Vasempaa yläkulmaa lähestyvät tuotteet myyvät vähän, mutta kate on erinomainen -> Kärsisikö hintaa laskea? Nostaisiko tämä tuotteiden myyntiä ja sitä kautta myös kokonaisuudessaan yrityksen katetta?
- Vasempaa alakulmaa lähestyvät tuotteet myyvät vähän ja huonolla katteella -> Kannattaako näitä tuotteita ylipäätänsä myydä,? Voisiko näiden hintaa nostaa?
Yllä oleva analyysi on aika väkevästi yksinkertaistettu, koska erityisesti kohdissa 2, 3 ja 4 olisi ennen muutoksia lisäksi hyvä ymmärtää, onko niillä merkitystä muiden tuotteiden myyntiin. Eli käytännössä onko hyväkatteiset tuotteet itseasiassa lisämyyntituotteita, joita saadaan myytyä siitä syystä, että olemme myyneet huonolla katteella joitakin toisia tuotteita?
Kuvitellaan että olen saanut toimeksiannon, jossa minun pitää ehdottaa muutoksia tuoteportfolioon/hinnoitteluun, jotta yrityksen katetta voidaan parantaa. Ehdotuksilla on kiire ja tulokset pitää olla tunnistettavissa nopeasti.
Lähestymistapoja on monia, mutta päätän lähteä metsästämään tuotteita, joita myydään vähän ja huonolla katteella. Tuumaan että voisi olla helpointa lähestyä asiaa lisäämällä molemmille akseleilla keskiarvoviivat, jotka muodostavat nelikentän.
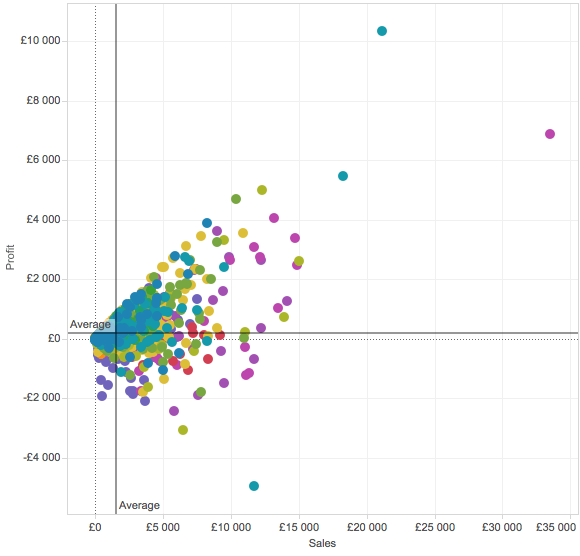
Täräytin nyt samalla pisteiden värityksen tuoteryhmätasolla, värien käyttö on yksi hyvä lisämauste myös scatteriin. Joillakin työkaluilla visualisointia voi maustaa vielä lisäksi merkin koolla ja tyypillä. Yhdistelemällä eri mahdollisuuksia visualisoida, datasta aukeaa heti enemmän tietoa.
Scatteriin muodostui nyt keskiarvojen perusteella nelikenttä, josta voin erottaa tuotteet sen perusteella onko niiden kate/myynti keskiarvoa vähemmän/enemmän. Olen siis erityisen kiinnostunut laatikosta vasemmassa alakulmassa. Ei millään kärsisi tehdä liikkuja, joiden takia hommat menee huonompaan suuntaan. Näinpä haluan vähän tutkia asiaa enemmän, enkä pelkästään listata vasemman alalaidan tuotteita ja ehdottaa nostamaan niiden hintoja.
Teen vielä pari temppua ja muodostan uuden scatterin:
- Valitsen pelkästään vasemman alakulman tuotteet ja rajaan muut tuotteet pois
- Rajaan tietoa niin, että otan mukaan vain tuotteet, joita on myyty viimeisen vuoden aikana ja jokainen kuukausi
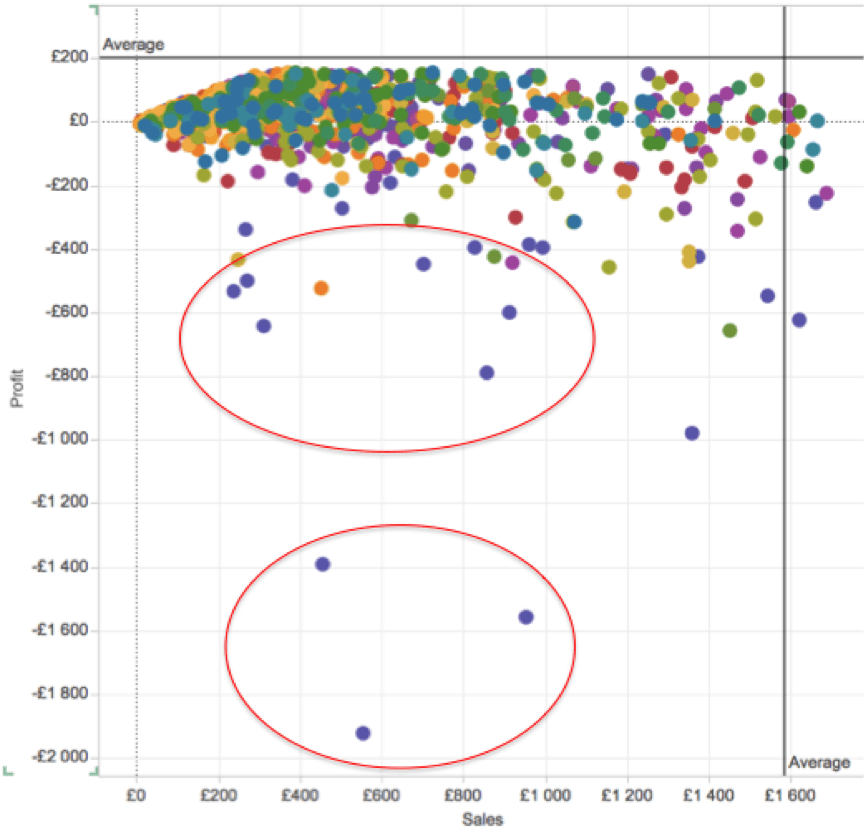
No mitäs tästä nyt voisi sitten tulkita? Päätän ehdottaa johdolle, että alalaidan kolmen tuotteen myynnin lopettaminen olisi hyvä ottaa tutkintaan ja yläpuolelta löytyvän kymmenen tuotteen nipun hinnan nostoa olisi syytä harkita. Laskelmani mukaan kyseisten tuotteet hintaa pitäisi nostaa keskimäärin XX %, jotta ne yhteensä yltäisivät katteessa keskiarvon tasolle (ja samalla kate olisi positiivinen).
Samalla scatterista huomaa, että itseasiassa matalakatteisista tuotteista iso osa on saman värisiä, eikö niin (violetti)? Hmmmm, ettei meillä vain olisi tuoteryhmä, joka on kokonaisuudessaan kannattamaton? Tarkemman tutkimisen jälkeen huomaan, että kyseinen tuoteryhmä XYZ on itseasiassa kannattamaton ja kokonaismyynnistä kateprosentti on n. – 20%. Päädyn edellisten lisäksi ehdottamaan johdolle, että tätä tuoteryhmää pitäisi tutkia tarkemmin tuotekehityksen kanssa ja tunnistaa tarvitaanko koko tuoteryhmää tai pystytäänkö katetta nostamaan riittävästi.
Tämän esimerkin tapauksessa scatter osoittautui arvokkaaksi lisätyökaluksi, jolla isosta datamassasta saatiin kaivettua johdolle arvokasta faktatietoa kannattamattomista tuoteryhmistä. Pelkkiä taulukoita ja tunnuslukuja tuijottamalla tämä tieto hukkuu helposti muiden tulosten sekaan ja sitä voi olla hankala saada nostettua esiin. Visualisoimalla dataa scatter kuviolla, oikeilla rajauksilla ja luokitteluilla tulos kuitenkin saatiin kaivettua esiin.


